

Technology for Uptime: Tools for FMs Managing Mission-Critical Spaces
In mission-critical facilities, there’s one KPI that matters most: Uptime. Whether it’s a hospital operating room, a pharmaceutical cleanroom, a research vivarium, or a high-tech manufacturing line, a single failure can risk lives, derail R&D, spoil product batches, and incur massive costs.
Facility managers (FMs) responsible for these environments live in a world of near-zero tolerance for outages. As Michael Conway of GMC Commissioning (commissioning service provider for laboratory and pharma clients) told us, “resilience and uptime are number one, safety is number two,” and everything else falls in line after that, including energy savings.
This mindset makes sense when you consider the stakes: unplanned downtime in pharmaceutical manufacturing can cost $100,000 to $500,000 per hour, and the average hospital loses $7,900 per minute when critical systems go down.
Yet keeping complex facilities online 24/7 is a daily battle. FMs are pragmatic, busy professionals, often firefighting problems before they snowball. They are also skeptical of hype —if a new technology can’t tangibly reduce their headaches, they have no time for it. In this article, we explore how technology can genuinely improve uptime in mission-critical spaces across healthcare, pharma, higher ed, and manufacturing.
We spoke with experts on the front lines: Conway, Alex Grace of Clockworks Analytics (who provides fault detection software to critical facilities), and Jim Meacham’s team at Altura Associates (a firm delivering commissioning and master systems integration in hospitals and campuses).
They told us technology is helping FMs in critical environments in three powerful ways: proving compliance, identifying and diagnosing issues proactively, and minimizing downtime during mandatory upgrades.
Below, we walk through each of these, with real examples, to see how the right tech stack is boosting the #1 KPI these FMs care about.
Use Case #1: Proving Compliance
In highly regulated industries, FM isn’t just about keeping equipment running—it’s also about maintaining environmental conditions within strict parameters and proving it.
In healthcare, it’s the Joint Commission’s surprise inspections. In pharma facilities, the FDA conducts regular audits of production environments—if a sterile cleanroom “goes negative” on pressure even briefly, the facility must stop production, document the incident, and prove that no contaminated product was released. Rather than scrambling after the fact, facilities are investing in building automation and fault detection and diagnostics (FDD) that alert staff the moment conditions drift out of spec.
This means compliance and uptime are two sides of the same coin. FMs traditionally have managed this with clipboards and log sheets, manually recording temperatures, humidity, pressure, etc., during routine rounds. As Alex Grace of Clockworks Analytics shared, a surprising amount of this is still done on pen and paper—a labor-intensive, error-prone process.
To automate this work, Clockworks has developed digital compliance dashboards for hospital pharmacies (and other regulated spaces) that replace the old clipboards.
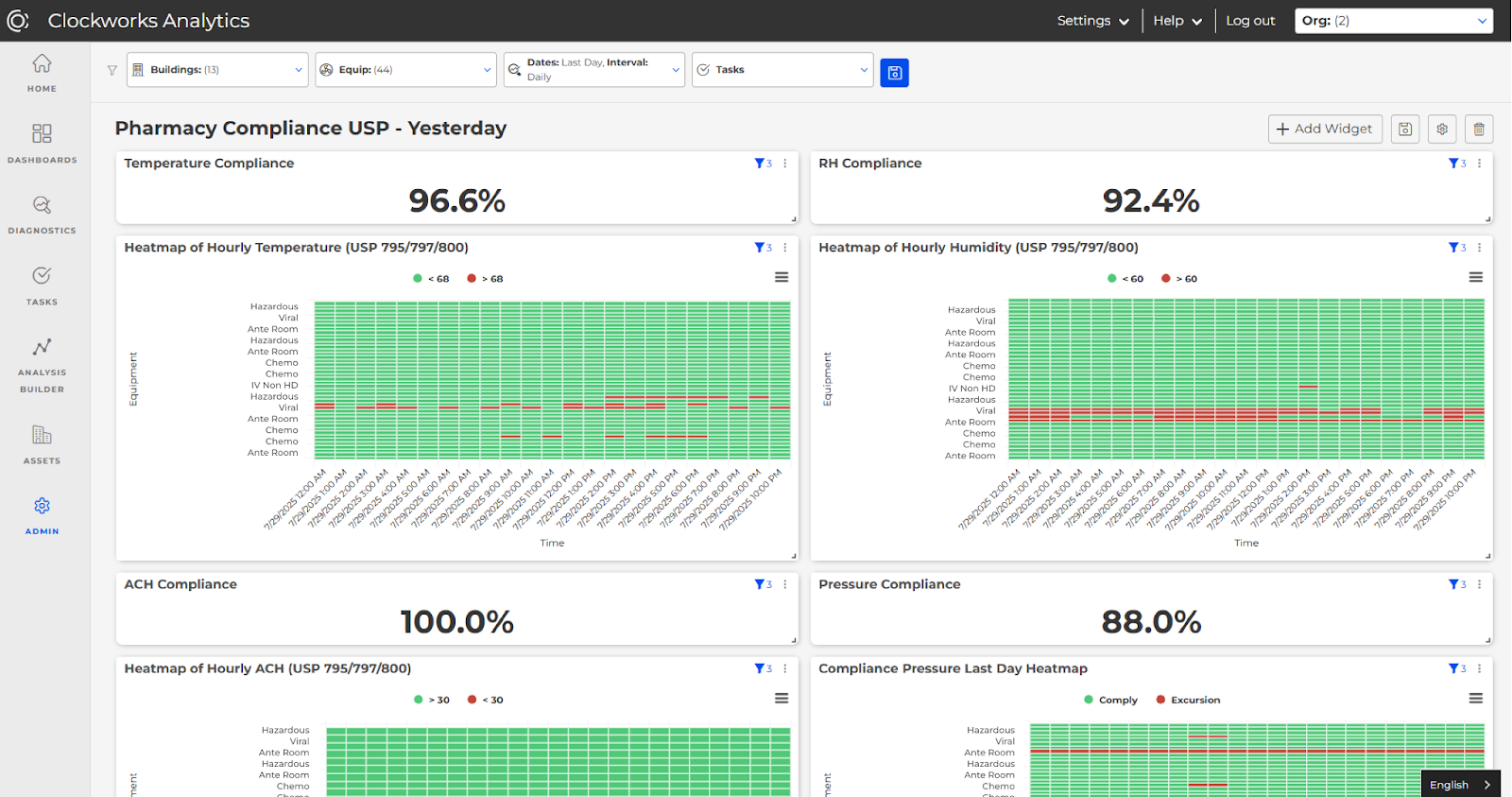
“Every box on that heat map is an hour of temperature, humidity, pressure… Every box that’s green… shows [everything is] good. And if it’s a box that’s red, it shows they were out of compliance for that hour and they need to do something,” Grace explains.
Tolerance thresholds are built in, so the moment any parameter goes out of range, it’s flagged. All of this creates an automatic record for regulators—essentially a permanent digital logbook. In other words, rather than an FM hoping those paper logs are filled and filed correctly, they can pull up a living dashboard that proves (to any auditor or higher-up) that, say, the negative air pressure in a lab was maintained 99.98% of the time last month—and pinpoint the exact 10 minutes it wasn’t, typically along with the real root cause (more on that in the next section) so that any deviation comes with an explanation of why it happened and how it was resolved.
An FM can now spend 5 minutes checking a dashboard instead of many hours compiling paper log binders, and many more hours hunting down the “why” behind the problems.
Use Case #2: Identifying and Diagnosing Issues Proactively
For critical facilities, preventing downtime is better than scrambling to fix it. FMs are increasingly turning to fault detection and diagnostics (FDD) tools to catch problems early, ideally before spaces drift out of compliance or systems shut down.
The idea is straightforward: use analytics to spot degradation early and fix it before it becomes a 2 AM crisis.
Clockworks now lets users tag equipment and zones as “critical,” so an FM can automatically prioritize any faults affecting those areas. An HVAC issue threatening, say, an isolation room will jump to the top of the list, whereas a fault in an office might be ranked lower.
Crucially, these technologies can detect subtle anomalies that a human might miss during routine rounds. One great example Grace shared involved something as mundane as a bad sensor. In a pharmacy cleanroom, a drifting relative humidity sensor could spell trouble: if it starts reading inaccurately low, the control system might over-humidify or simply report false compliance data. Clockworks caught a critical RH sensor that read zero for 1.5 hours one day—a blip that staff likely overlooked.
“Sensors don’t go from working perfectly to not working at all—they start to fail,” Grace noted. By catching that early weird behavior, the team could replace or recalibrate the sensor before it flatlined entirely or caused an out-of-spec condition.
Multiply that by hundreds of sensors (for temperature, pressure, airflow, etc.) and you get a sense of how FDD systems act as tireless sentinels for an FM, watching trends and patterns that would be impossible to manually track.
And it’s not just FMs. Grace mentioned that some of their service provider partners are under performance-based Public-Private Partnership (P3) contracts where any downtime incurs hefty fines. One partner has even budgeted $9.5 million in downtime fines for this year. FDD literally pays for itself each time it prevents or shortens equipment downtime.
The Altura team shared a case at the University of Washington where a vivarium (lab animal facility) was served by a dedicated central utility plant. The plant’s large chillers were intermittently failing. A traditional approach might be to call the chiller vendor and reactively replace parts; instead, the Altura and facilities teams, armed with analytics (SkySpark integrated with the plant’s PLC controls), hunted for root causes in the data. They discovered that during low-load conditions, the sequencing was causing the chiller’s inlet guide vanes to rapidly cycle, essentially wearing them out.
Armed with this insight, they worked with the manufacturer to tweak the onboard chiller controls and adjusted the waterside economizer logic to keep the chiller out of that unstable low-load zone and end the downtime-causing failures. That same project snowballed into a treasure trove of other findings, including a faulty dehumidification sequence in a downstream lab building and the discovery of a closed 6-inch bypass valve wasting 30% of pumping energy.
As Altura’s Tom Pine put it, “you never know what you’re going to find” once you start digging into the data. What began as an uptime project also ended up improving efficiency and performance. The UW plant manager, initially focused only on reliability, became a data evangelist and spread these practices to the main campus plant, seeing that better uptime and energy optimization can go hand in hand once you have good data.
Most issues threatening uptime in these facilities are not exotic or headline-grabbing; often, they’re mundane things like stuck dampers, fouled filters, drifting sensors, or misprogrammed sequences. Grace underscored this, saying that faults which bring down critical equipment are usually “nothing special.”
Conway emphasized that before you can detect a fault, the system actually has to be monitoring the right things. On new construction projects, GMC often works backwards from the owner’s operational priorities to identify gaps in controls design. “If a facility wants to know whether an actuator failed, we ask: is there a feedback point in the design?” says Michael Conway.
In most designs, the monitoring points needed for diagnostics—like valve feedback, differential pressure, or humidity trends—are omitted to save costs or because they were not explicitly requested. Conway calls this “tailor-fitting the BAS to the needs of the space.”
The playbook: focus on the fundamentals first (ensure you have the right sensors, valves, and actuators) and use analytics to continuously watch them.
Use Case #3: Minimizing Downtime During Upgrades and Changes
Even with perfect maintenance and compliance, every critical space and system eventually needs planned downtime for upgrading or replacing major systems. Managing retrofits, expansions, and cutovers in a mission-critical environment is a high-wire act for FMs—but technology can help reduce the downtime required.
[Members can log in to hear the story of how Altura is helping Kaiser Permanente replace an old JCI BAS with a new Distech system, while the hospital maintains full operation.]
In this realm, it’s not just the software or analytics, but also the design of the control systems and networks that determines how flexible you can be when making changes. Our conversation with Altura’s team about a long-term BAS upgrade at Kaiser Permanente’s Baldwin Park hospital was eye-opening.
Baldwin Park is a 1 million sq. ft. medical center with dozens of operating rooms, pharmacies, labs. A few years ago, the facility embarked on a multi-year project to replace an old Johnson Controls BAS with a new Distech system, wing by wing, while the hospital remained 24/7 operational.
The team is minimizing downtime with an aggressive strategy of phased overnight cutovers with extensive preparation. Altura’s Sia Dabiri described it: “everything… from switching the equipment to installation and commissioning and TAB and sign-off… is all done within 12 hours.” Achieving this is an enormous technical and logistical feat, and it only works with the right technology backbone and process in place.
One key enabler is having an open, modular BAS architecture, as detailed in our 2020 article The BAS Architecture of the Future. That future is now here: Kaiser Permanente’s standard is to run a Niagara-based supervisory server on a virtual machine, with open protocol (BACnet/IP) controllers beneath it.
This openness paid off in a big way when, about a year into the project, the original controls installer (the Distech vendor) couldn’t keep up with the schedule and had to bow out. In a proprietary system world, that would be a nightmare scenario—switching BAS vendors mid-project could mean starting from scratch (since Vendor B’s system wouldn’t talk to Vendor A’s). But because of the open architecture, the general contractor was able to hire a new controls firm to step in, and Altura’s team (as the MSI) could slot them in with minimal disruption.
All the front-end graphics and supervisory logic were on Niagara (standardized), and Altura even had the capability in-house to program and bench-test the Distech controllers themselves. This meant the handover from one vendor to the next was smooth—no rip-and-replace needed, no extended downtime, just a swap of contractors. The BAS architecture gave the owner leverage and flexibility, ultimately keeping the upgrade timeline on track and avoiding prolonged outages.
Technology also shines in how the team minimizes the actual cutover downtime. Long before any switch flipped, the team was rebuilding databases and graphics offline, bench-testing controllers with the sequences for the new system, and performing pre-functional testing in a sandbox environment. Weeks ahead of a scheduled cutover, they use SkySpark to run automated functional tests on the equipment in question, generating reports of any control issues or calibration problems that would trip up the commissioning. The facilities staff and contractors could then fix those issues in advance.
By the time the actual night of the cutover arrived, 80-90% of the “unknowns” were already vetted—so it was likelier that when the new system came online, everything would work on the first go. This approach drastically reduced the need for trial-and-error during the outage window. It also avoided repeated disruptive testing.
“They want to avoid all these overnight testings, because every time they have to do overnight testing, they have to cancel surgeries, they have to cancel patients,” Sia explained. By leveraging analytics and thorough planning, they ensured that most verifications were done virtually or in a controlled way, leaving only the absolute must-do tasks for the short cutover window.
During the cutover itself, technology provides an extra safety net. In such a project, there is always the fear: what if the new system doesn’t come up clean by morning? To mitigate that, the team did a few clever things. They had the analytics system “data pipeline” already in place watching the data from the moment of switchover.
“You can do a lot of pre-testing with analytics, and then you can do immediate testing once you’re cut over because that analytics pipeline is already in place,” Meacham explains. In other words, the second the new BAS started controlling the OR room, the FDD platform was reading the sensors and verifying that temperature, humidity, pressurization, etc. were all as required.
All these layers of technology—open architecture, virtualization, parallel systems, analytics-driven testing—combine to make an incredibly difficult upgrade successful without any unplanned downtime.
Maintaining uptime during major changes requires aligning your technology stack with resilience from the get-go. From our discussions, a few key ingredients emerged as must-haves for mission-critical facilities:
- A data model that flags critical assets and conditions: Your building systems should know which spaces and equipment are mission-critical so that during both daily operations and upgrades, those get priority.
- Customized control system design (no copy-paste specs): Mission-critical facilities benefit from BAS and controls designed for their specific needs—not a generic template. Every sequence, alarm, and integration point should be thought through with reliability in mind, not just energy or first cost.
- A resilient network and integration architecture: Downtime can easily result from single points of failure in the control system architecture. Network designs need to withstand outages with redundant controllers, backup communication paths, and local fail-safes. No vendor lock-in means no hostages to someone else’s timeline or mistakes.
Keep it online
Facilities managers of mission-critical spaces have a singular mandate: keep it online. All the energy savings, occupant comfort, or other nice-to-haves mean little if the surgery gets canceled, the experiment is ruined, or the production line stops. FMs are skeptical for good reason: they’ve seen “smart” tech make things dumber when it’s deployed without regard for resilience.
In the end, mission-critical facilities will always be high-wire acts—but with the right tools, FMs don’t have to work without a net. The fire-fighting mentality is giving way (gradually) to a data-driven, proactive ops culture.
Uptime is becoming a science, not just an art. The surgeons, scientists, engineers, and students depending on your facility don’t care how fancy your analytics look or how “open” your BAS is – they care that the lights stay on, the air stays clean, and the mission never stops.
In this realm, it’s not just the software or analytics, but also the design of the control systems and networks that determines how flexible you can be when making changes. Our conversation with Altura’s team about a long-term BAS upgrade at Kaiser Permanente’s Baldwin Park hospital was eye-opening.
Baldwin Park is a 1 million sq. ft. medical center with dozens of operating rooms, pharmacies, labs. A few years ago, the facility embarked on a multi-year project to replace an old Johnson Controls BAS with a new Distech system, wing by wing, while the hospital remained 24/7 operational.
The team is minimizing downtime with an aggressive strategy of phased overnight cutovers with extensive preparation. Altura’s Sia Dabiri described it: “everything… from switching the equipment to installation and commissioning and TAB and sign-off… is all done within 12 hours.” Achieving this is an enormous technical and logistical feat, and it only works with the right technology backbone and process in place.
One key enabler is having an open, modular BAS architecture, as detailed in our 2020 article The BAS Architecture of the Future. That future is now here: Kaiser Permanente’s standard is to run a Niagara-based supervisory server on a virtual machine, with open protocol (BACnet/IP) controllers beneath it.
This openness paid off in a big way when, about a year into the project, the original controls installer (the Distech vendor) couldn’t keep up with the schedule and had to bow out. In a proprietary system world, that would be a nightmare scenario—switching BAS vendors mid-project could mean starting from scratch (since Vendor B’s system wouldn’t talk to Vendor A’s). But because of the open architecture, the general contractor was able to hire a new controls firm to step in, and Altura’s team (as the MSI) could slot them in with minimal disruption.
All the front-end graphics and supervisory logic were on Niagara (standardized), and Altura even had the capability in-house to program and bench-test the Distech controllers themselves. This meant the handover from one vendor to the next was smooth—no rip-and-replace needed, no extended downtime, just a swap of contractors. The BAS architecture gave the owner leverage and flexibility, ultimately keeping the upgrade timeline on track and avoiding prolonged outages.
Technology also shines in how the team minimizes the actual cutover downtime. Long before any switch flipped, the team was rebuilding databases and graphics offline, bench-testing controllers with the sequences for the new system, and performing pre-functional testing in a sandbox environment. Weeks ahead of a scheduled cutover, they use SkySpark to run automated functional tests on the equipment in question, generating reports of any control issues or calibration problems that would trip up the commissioning. The facilities staff and contractors could then fix those issues in advance.
By the time the actual night of the cutover arrived, 80-90% of the “unknowns” were already vetted—so it was likelier that when the new system came online, everything would work on the first go. This approach drastically reduced the need for trial-and-error during the outage window. It also avoided repeated disruptive testing.
“They want to avoid all these overnight testings, because every time they have to do overnight testing, they have to cancel surgeries, they have to cancel patients,” Sia explained. By leveraging analytics and thorough planning, they ensured that most verifications were done virtually or in a controlled way, leaving only the absolute must-do tasks for the short cutover window.
During the cutover itself, technology provides an extra safety net. In such a project, there is always the fear: what if the new system doesn’t come up clean by morning? To mitigate that, the team did a few clever things. They had the analytics system “data pipeline” already in place watching the data from the moment of switchover.
“You can do a lot of pre-testing with analytics, and then you can do immediate testing once you’re cut over because that analytics pipeline is already in place,” Meacham explains. In other words, the second the new BAS started controlling the OR room, the FDD platform was reading the sensors and verifying that temperature, humidity, pressurization, etc. were all as required.
All these layers of technology—open architecture, virtualization, parallel systems, analytics-driven testing—combine to make an incredibly difficult upgrade successful without any unplanned downtime.
Maintaining uptime during major changes requires aligning your technology stack with resilience from the get-go. From our discussions, a few key ingredients emerged as must-haves for mission-critical facilities:
- A data model that flags critical assets and conditions: Your building systems should know which spaces and equipment are mission-critical so that during both daily operations and upgrades, those get priority.
- Customized control system design (no copy-paste specs): Mission-critical facilities benefit from BAS and controls designed for their specific needs—not a generic template. Every sequence, alarm, and integration point should be thought through with reliability in mind, not just energy or first cost.
- A resilient network and integration architecture: Downtime can easily result from single points of failure in the control system architecture. Network designs need to withstand outages with redundant controllers, backup communication paths, and local fail-safes. No vendor lock-in means no hostages to someone else’s timeline or mistakes.
Keep it online
Facilities managers of mission-critical spaces have a singular mandate: keep it online. All the energy savings, occupant comfort, or other nice-to-haves mean little if the surgery gets canceled, the experiment is ruined, or the production line stops. FMs are skeptical for good reason: they’ve seen “smart” tech make things dumber when it’s deployed without regard for resilience.
In the end, mission-critical facilities will always be high-wire acts—but with the right tools, FMs don’t have to work without a net. The fire-fighting mentality is giving way (gradually) to a data-driven, proactive ops culture.
Uptime is becoming a science, not just an art. The surgeons, scientists, engineers, and students depending on your facility don’t care how fancy your analytics look or how “open” your BAS is – they care that the lights stay on, the air stays clean, and the mission never stops.
In this realm, it’s not just the software or analytics, but also the design of the control systems and networks that determines how flexible you can be when making changes. Our conversation with Altura’s team about a long-term BAS upgrade at Kaiser Permanente’s Baldwin Park hospital was eye-opening.
Baldwin Park is a 1 million sq. ft. medical center with dozens of operating rooms, pharmacies, labs. A few years ago, the facility embarked on a multi-year project to replace an old Johnson Controls BAS with a new Distech system, wing by wing, while the hospital remained 24/7 operational.
The team is minimizing downtime with an aggressive strategy of phased overnight cutovers with extensive preparation. Altura’s Sia Dabiri described it: “everything… from switching the equipment to installation and commissioning and TAB and sign-off… is all done within 12 hours.” Achieving this is an enormous technical and logistical feat, and it only works with the right technology backbone and process in place.
One key enabler is having an open, modular BAS architecture, as detailed in our 2020 article The BAS Architecture of the Future. That future is now here: Kaiser Permanente’s standard is to run a Niagara-based supervisory server on a virtual machine, with open protocol (BACnet/IP) controllers beneath it.
This openness paid off in a big way when, about a year into the project, the original controls installer (the Distech vendor) couldn’t keep up with the schedule and had to bow out. In a proprietary system world, that would be a nightmare scenario—switching BAS vendors mid-project could mean starting from scratch (since Vendor B’s system wouldn’t talk to Vendor A’s). But because of the open architecture, the general contractor was able to hire a new controls firm to step in, and Altura’s team (as the MSI) could slot them in with minimal disruption.
All the front-end graphics and supervisory logic were on Niagara (standardized), and Altura even had the capability in-house to program and bench-test the Distech controllers themselves. This meant the handover from one vendor to the next was smooth—no rip-and-replace needed, no extended downtime, just a swap of contractors. The BAS architecture gave the owner leverage and flexibility, ultimately keeping the upgrade timeline on track and avoiding prolonged outages.
Technology also shines in how the team minimizes the actual cutover downtime. Long before any switch flipped, the team was rebuilding databases and graphics offline, bench-testing controllers with the sequences for the new system, and performing pre-functional testing in a sandbox environment. Weeks ahead of a scheduled cutover, they use SkySpark to run automated functional tests on the equipment in question, generating reports of any control issues or calibration problems that would trip up the commissioning. The facilities staff and contractors could then fix those issues in advance.
By the time the actual night of the cutover arrived, 80-90% of the “unknowns” were already vetted—so it was likelier that when the new system came online, everything would work on the first go. This approach drastically reduced the need for trial-and-error during the outage window. It also avoided repeated disruptive testing.
“They want to avoid all these overnight testings, because every time they have to do overnight testing, they have to cancel surgeries, they have to cancel patients,” Sia explained. By leveraging analytics and thorough planning, they ensured that most verifications were done virtually or in a controlled way, leaving only the absolute must-do tasks for the short cutover window.
During the cutover itself, technology provides an extra safety net. In such a project, there is always the fear: what if the new system doesn’t come up clean by morning? To mitigate that, the team did a few clever things. They had the analytics system “data pipeline” already in place watching the data from the moment of switchover.
“You can do a lot of pre-testing with analytics, and then you can do immediate testing once you’re cut over because that analytics pipeline is already in place,” Meacham explains. In other words, the second the new BAS started controlling the OR room, the FDD platform was reading the sensors and verifying that temperature, humidity, pressurization, etc. were all as required.
All these layers of technology—open architecture, virtualization, parallel systems, analytics-driven testing—combine to make an incredibly difficult upgrade successful without any unplanned downtime.
Maintaining uptime during major changes requires aligning your technology stack with resilience from the get-go. From our discussions, a few key ingredients emerged as must-haves for mission-critical facilities:
- A data model that flags critical assets and conditions: Your building systems should know which spaces and equipment are mission-critical so that during both daily operations and upgrades, those get priority.
- Customized control system design (no copy-paste specs): Mission-critical facilities benefit from BAS and controls designed for their specific needs—not a generic template. Every sequence, alarm, and integration point should be thought through with reliability in mind, not just energy or first cost.
- A resilient network and integration architecture: Downtime can easily result from single points of failure in the control system architecture. Network designs need to withstand outages with redundant controllers, backup communication paths, and local fail-safes. No vendor lock-in means no hostages to someone else’s timeline or mistakes.
Keep it online
Facilities managers of mission-critical spaces have a singular mandate: keep it online. All the energy savings, occupant comfort, or other nice-to-haves mean little if the surgery gets canceled, the experiment is ruined, or the production line stops. FMs are skeptical for good reason: they’ve seen “smart” tech make things dumber when it’s deployed without regard for resilience.
In the end, mission-critical facilities will always be high-wire acts—but with the right tools, FMs don’t have to work without a net. The fire-fighting mentality is giving way (gradually) to a data-driven, proactive ops culture.
Uptime is becoming a science, not just an art. The surgeons, scientists, engineers, and students depending on your facility don’t care how fancy your analytics look or how “open” your BAS is – they care that the lights stay on, the air stays clean, and the mission never stops.
In mission-critical facilities, there’s one KPI that matters most: Uptime. Whether it’s a hospital operating room, a pharmaceutical cleanroom, a research vivarium, or a high-tech manufacturing line, a single failure can risk lives, derail R&D, spoil product batches, and incur massive costs.
Facility managers (FMs) responsible for these environments live in a world of near-zero tolerance for outages. As Michael Conway of GMC Commissioning (commissioning service provider for laboratory and pharma clients) told us, “resilience and uptime are number one, safety is number two,” and everything else falls in line after that, including energy savings.
This mindset makes sense when you consider the stakes: unplanned downtime in pharmaceutical manufacturing can cost $100,000 to $500,000 per hour, and the average hospital loses $7,900 per minute when critical systems go down.
Yet keeping complex facilities online 24/7 is a daily battle. FMs are pragmatic, busy professionals, often firefighting problems before they snowball. They are also skeptical of hype —if a new technology can’t tangibly reduce their headaches, they have no time for it. In this article, we explore how technology can genuinely improve uptime in mission-critical spaces across healthcare, pharma, higher ed, and manufacturing.
We spoke with experts on the front lines: Conway, Alex Grace of Clockworks Analytics (who provides fault detection software to critical facilities), and Jim Meacham’s team at Altura Associates (a firm delivering commissioning and master systems integration in hospitals and campuses).
They told us technology is helping FMs in critical environments in three powerful ways: proving compliance, identifying and diagnosing issues proactively, and minimizing downtime during mandatory upgrades.
Below, we walk through each of these, with real examples, to see how the right tech stack is boosting the #1 KPI these FMs care about.
Use Case #1: Proving Compliance
In highly regulated industries, FM isn’t just about keeping equipment running—it’s also about maintaining environmental conditions within strict parameters and proving it.
In healthcare, it’s the Joint Commission’s surprise inspections. In pharma facilities, the FDA conducts regular audits of production environments—if a sterile cleanroom “goes negative” on pressure even briefly, the facility must stop production, document the incident, and prove that no contaminated product was released. Rather than scrambling after the fact, facilities are investing in building automation and fault detection and diagnostics (FDD) that alert staff the moment conditions drift out of spec.
This means compliance and uptime are two sides of the same coin. FMs traditionally have managed this with clipboards and log sheets, manually recording temperatures, humidity, pressure, etc., during routine rounds. As Alex Grace of Clockworks Analytics shared, a surprising amount of this is still done on pen and paper—a labor-intensive, error-prone process.
To automate this work, Clockworks has developed digital compliance dashboards for hospital pharmacies (and other regulated spaces) that replace the old clipboards.
“Every box on that heat map is an hour of temperature, humidity, pressure… Every box that’s green… shows [everything is] good. And if it’s a box that’s red, it shows they were out of compliance for that hour and they need to do something,” Grace explains.
Tolerance thresholds are built in, so the moment any parameter goes out of range, it’s flagged. All of this creates an automatic record for regulators—essentially a permanent digital logbook. In other words, rather than an FM hoping those paper logs are filled and filed correctly, they can pull up a living dashboard that proves (to any auditor or higher-up) that, say, the negative air pressure in a lab was maintained 99.98% of the time last month—and pinpoint the exact 10 minutes it wasn’t, typically along with the real root cause (more on that in the next section) so that any deviation comes with an explanation of why it happened and how it was resolved.
An FM can now spend 5 minutes checking a dashboard instead of many hours compiling paper log binders, and many more hours hunting down the “why” behind the problems.
Use Case #2: Identifying and Diagnosing Issues Proactively
For critical facilities, preventing downtime is better than scrambling to fix it. FMs are increasingly turning to fault detection and diagnostics (FDD) tools to catch problems early, ideally before spaces drift out of compliance or systems shut down.
The idea is straightforward: use analytics to spot degradation early and fix it before it becomes a 2 AM crisis.
Clockworks now lets users tag equipment and zones as “critical,” so an FM can automatically prioritize any faults affecting those areas. An HVAC issue threatening, say, an isolation room will jump to the top of the list, whereas a fault in an office might be ranked lower.
Crucially, these technologies can detect subtle anomalies that a human might miss during routine rounds. One great example Grace shared involved something as mundane as a bad sensor. In a pharmacy cleanroom, a drifting relative humidity sensor could spell trouble: if it starts reading inaccurately low, the control system might over-humidify or simply report false compliance data. Clockworks caught a critical RH sensor that read zero for 1.5 hours one day—a blip that staff likely overlooked.
“Sensors don’t go from working perfectly to not working at all—they start to fail,” Grace noted. By catching that early weird behavior, the team could replace or recalibrate the sensor before it flatlined entirely or caused an out-of-spec condition.
Multiply that by hundreds of sensors (for temperature, pressure, airflow, etc.) and you get a sense of how FDD systems act as tireless sentinels for an FM, watching trends and patterns that would be impossible to manually track.
And it’s not just FMs. Grace mentioned that some of their service provider partners are under performance-based Public-Private Partnership (P3) contracts where any downtime incurs hefty fines. One partner has even budgeted $9.5 million in downtime fines for this year. FDD literally pays for itself each time it prevents or shortens equipment downtime.
The Altura team shared a case at the University of Washington where a vivarium (lab animal facility) was served by a dedicated central utility plant. The plant’s large chillers were intermittently failing. A traditional approach might be to call the chiller vendor and reactively replace parts; instead, the Altura and facilities teams, armed with analytics (SkySpark integrated with the plant’s PLC controls), hunted for root causes in the data. They discovered that during low-load conditions, the sequencing was causing the chiller’s inlet guide vanes to rapidly cycle, essentially wearing them out.
Armed with this insight, they worked with the manufacturer to tweak the onboard chiller controls and adjusted the waterside economizer logic to keep the chiller out of that unstable low-load zone and end the downtime-causing failures. That same project snowballed into a treasure trove of other findings, including a faulty dehumidification sequence in a downstream lab building and the discovery of a closed 6-inch bypass valve wasting 30% of pumping energy.
As Altura’s Tom Pine put it, “you never know what you’re going to find” once you start digging into the data. What began as an uptime project also ended up improving efficiency and performance. The UW plant manager, initially focused only on reliability, became a data evangelist and spread these practices to the main campus plant, seeing that better uptime and energy optimization can go hand in hand once you have good data.
Most issues threatening uptime in these facilities are not exotic or headline-grabbing; often, they’re mundane things like stuck dampers, fouled filters, drifting sensors, or misprogrammed sequences. Grace underscored this, saying that faults which bring down critical equipment are usually “nothing special.”
Conway emphasized that before you can detect a fault, the system actually has to be monitoring the right things. On new construction projects, GMC often works backwards from the owner’s operational priorities to identify gaps in controls design. “If a facility wants to know whether an actuator failed, we ask: is there a feedback point in the design?” says Michael Conway.
In most designs, the monitoring points needed for diagnostics—like valve feedback, differential pressure, or humidity trends—are omitted to save costs or because they were not explicitly requested. Conway calls this “tailor-fitting the BAS to the needs of the space.”
The playbook: focus on the fundamentals first (ensure you have the right sensors, valves, and actuators) and use analytics to continuously watch them.
Use Case #3: Minimizing Downtime During Upgrades and Changes
Even with perfect maintenance and compliance, every critical space and system eventually needs planned downtime for upgrading or replacing major systems. Managing retrofits, expansions, and cutovers in a mission-critical environment is a high-wire act for FMs—but technology can help reduce the downtime required.
[Members can log in to hear the story of how Altura is helping Kaiser Permanente replace an old JCI BAS with a new Distech system, while the hospital maintains full operation.]


This is a great piece!
I agree.